Flujo de trabajo reproducible con R y {targets}
Laboratorio Abre Tu Ciencia
![]()
22 de enero de 2026
Targets
![]()
El paquete targets es una herramienta de pipeline para R enfocada en análisis estadístico y ciencia de datos: coordina una serie de pasos computacionales (llamados targets) y, al igual que otros sistemas de flujo de trabajo, evita recalcular pasos cuyos datos o código no han cambiado, lo que ahorra tiempo y mejora la reproducibilidad de proyectos complejos.
Cada target representa una tarea definida por funciones de R, y la estructura de dependencias entre ellos forma un gráfico acíclico dirigido (DAG) que targets utiliza para decidir qué ejecutar y qué saltarse.
Puedes ver toda la documentación aquí: Manual Repositorio
¿Por qué targets?
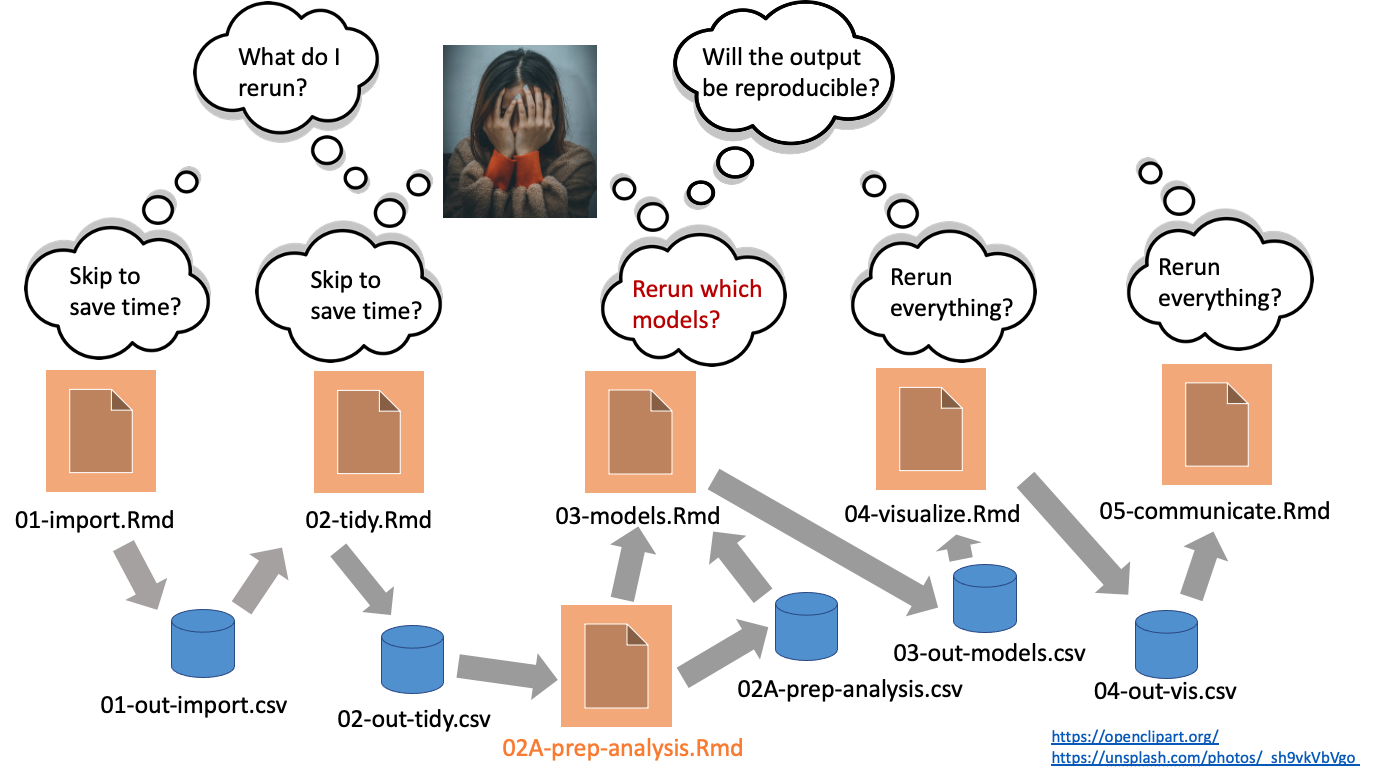
¿Qué debo volver a correr?, ¿puedo saltarme pasos para ahorrar tiempo?, ¿qué modelos específicos se ven afectados?, ¿tengo que rehacer todo para garantizar reproducibilidad?
Targets
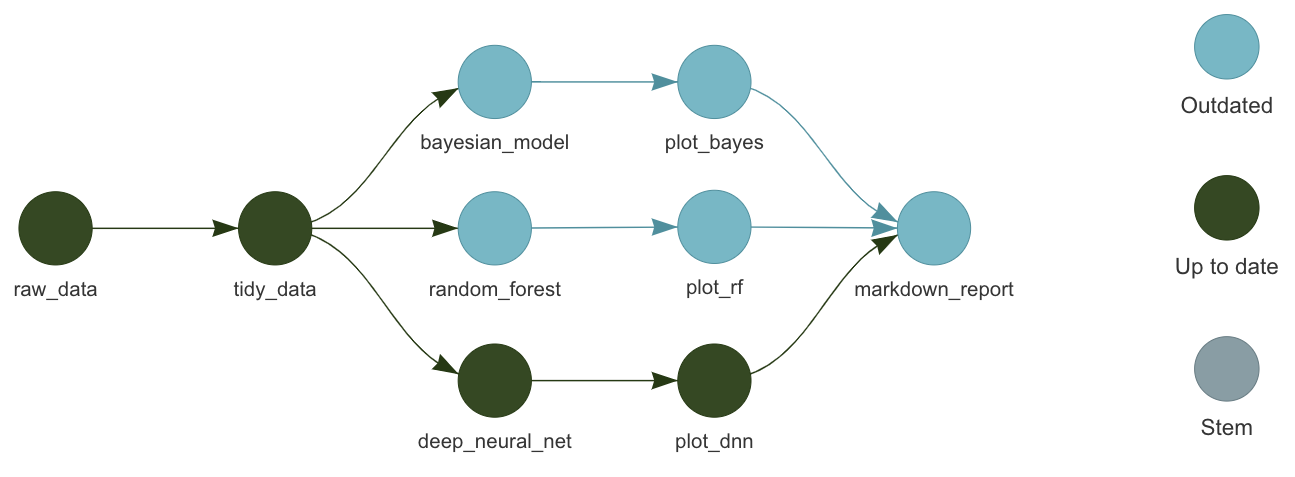
- Actualiza solo lo necesario.
- Cálculos escalables.
- Gestiona los datos de salida.
Universo Targets